Hardware-aware Multi-Cluster AI Serving Platform
흩어진 GPU 서버를 하나로 묶어, AI 모델을 최적의 하드웨어에 자동 배치
클라우드 없이도 AI를 가장 효율적으로 서빙하는 온프레미스 플랫폼. 복잡한 설정 없이, 웹 콘솔에서 모델을 선택하면 끝납니다.
PROBLEM
"배보다 배꼽이 큰" 서빙 비용
AI가 '구축'에서 '서비스'로 넘어가며, 서빙 비용이 새로운 병목이 됐습니다.
AI 시스템 생애주기 비용이 학습이 아니라 서빙에서 발생 — 학습은 한 번, 서빙은 365일 24시간 돌아갑니다. (Stanford AI Index 2025)
클라우드 GPU 단가. 서비스를 키울수록 서빙 인프라 비용이 서비스 자체보다 커집니다. 금융·공공은 보안 규정상 클라우드도 불가 → 자체 GPU 강제.
자기 GPU를 사도 제대로 쓸 SW가 없습니다. 기본 K8s는 GPU 물리 구조(NVLink/PCIe/NUMA)를 몰라 병목이 생기고, 비싼 GPU의 3/4이 놀고 있습니다.
SOLUTION
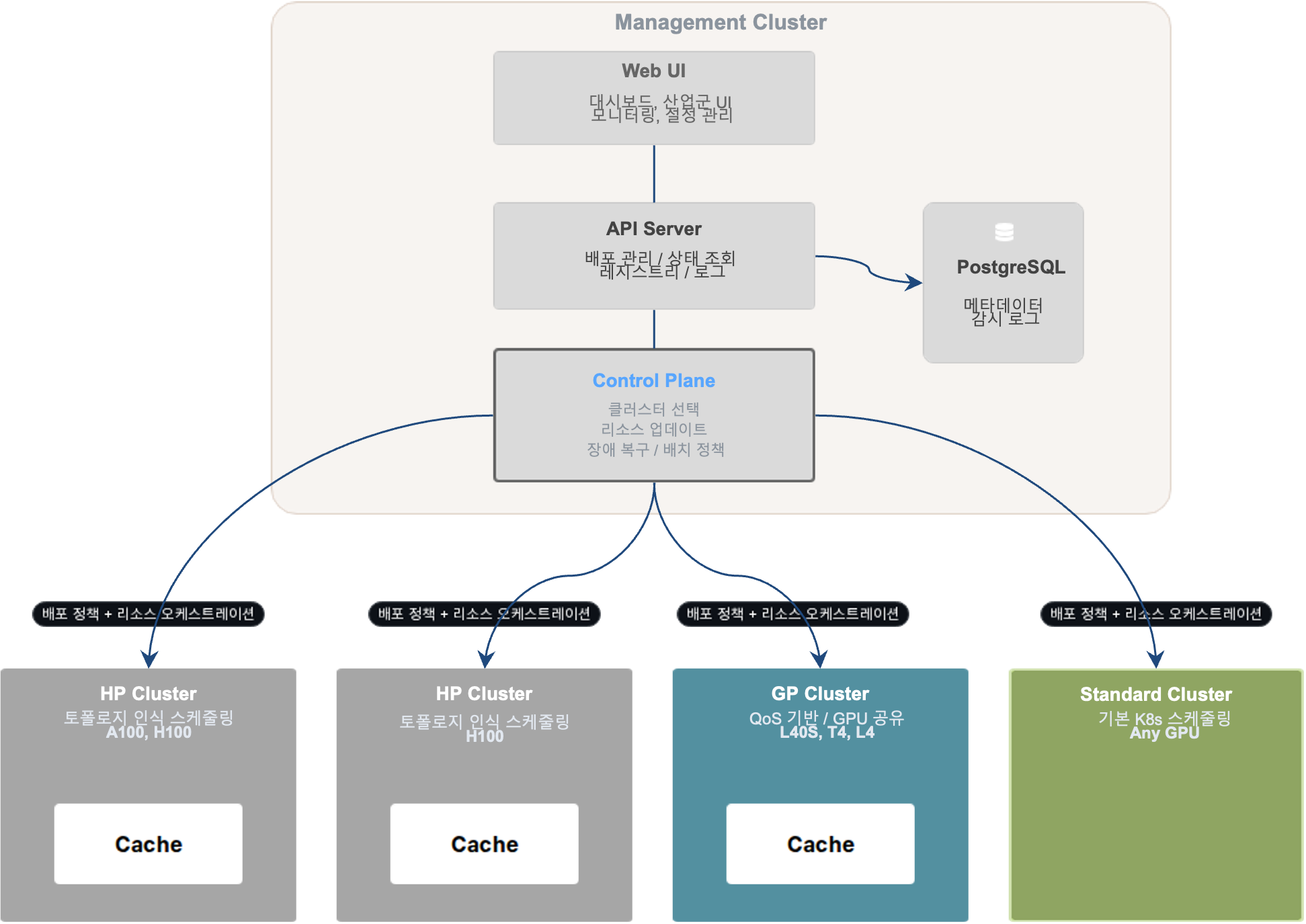
GPU를 묶고, 자동 배치하는 서빙 인프라
흩어진 GPU 서버를 하나의 컨트롤 플레인으로 묶고, 모델을 최적의 하드웨어에 자동 배치합니다.
HOW IT WORKS
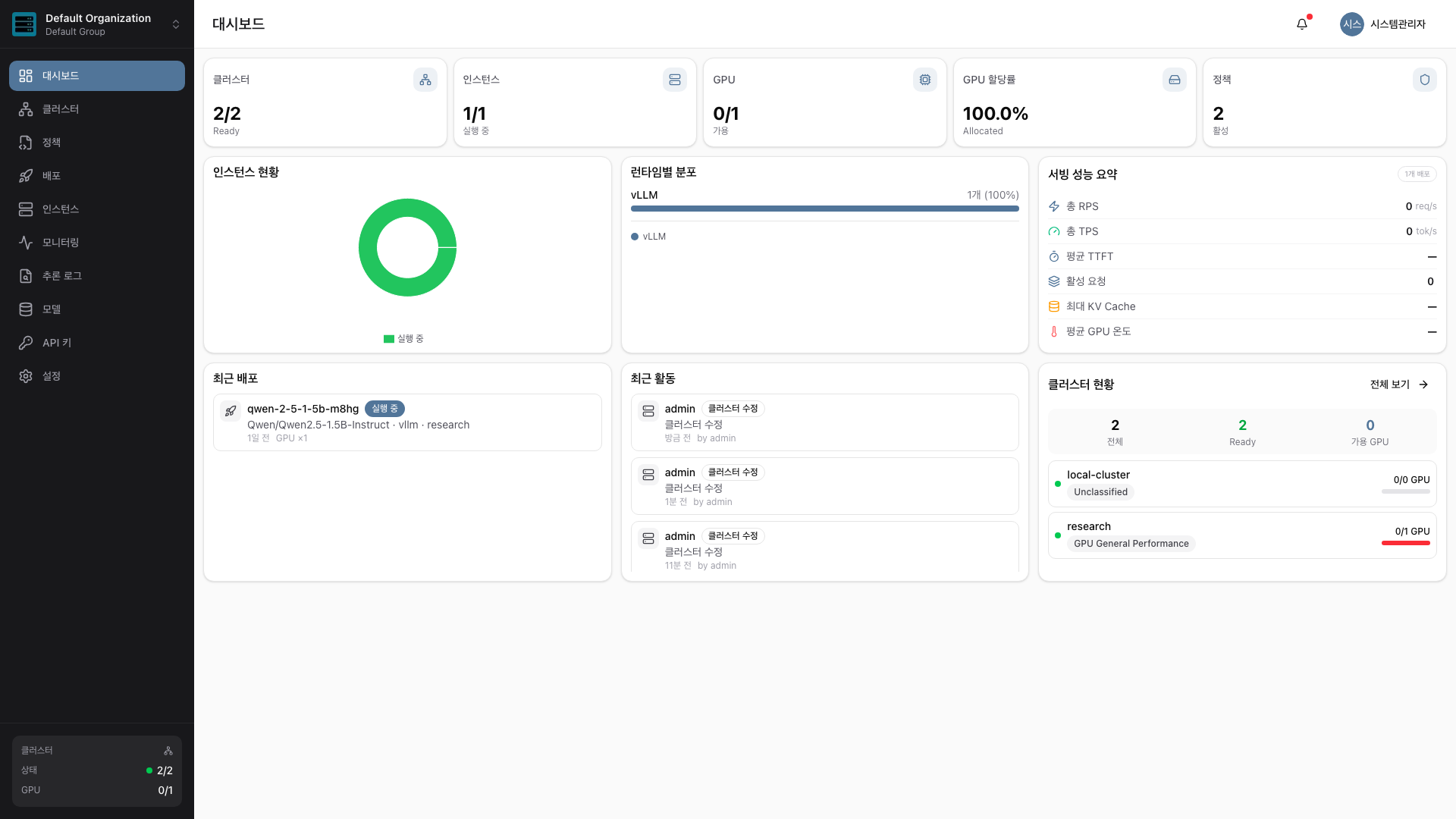
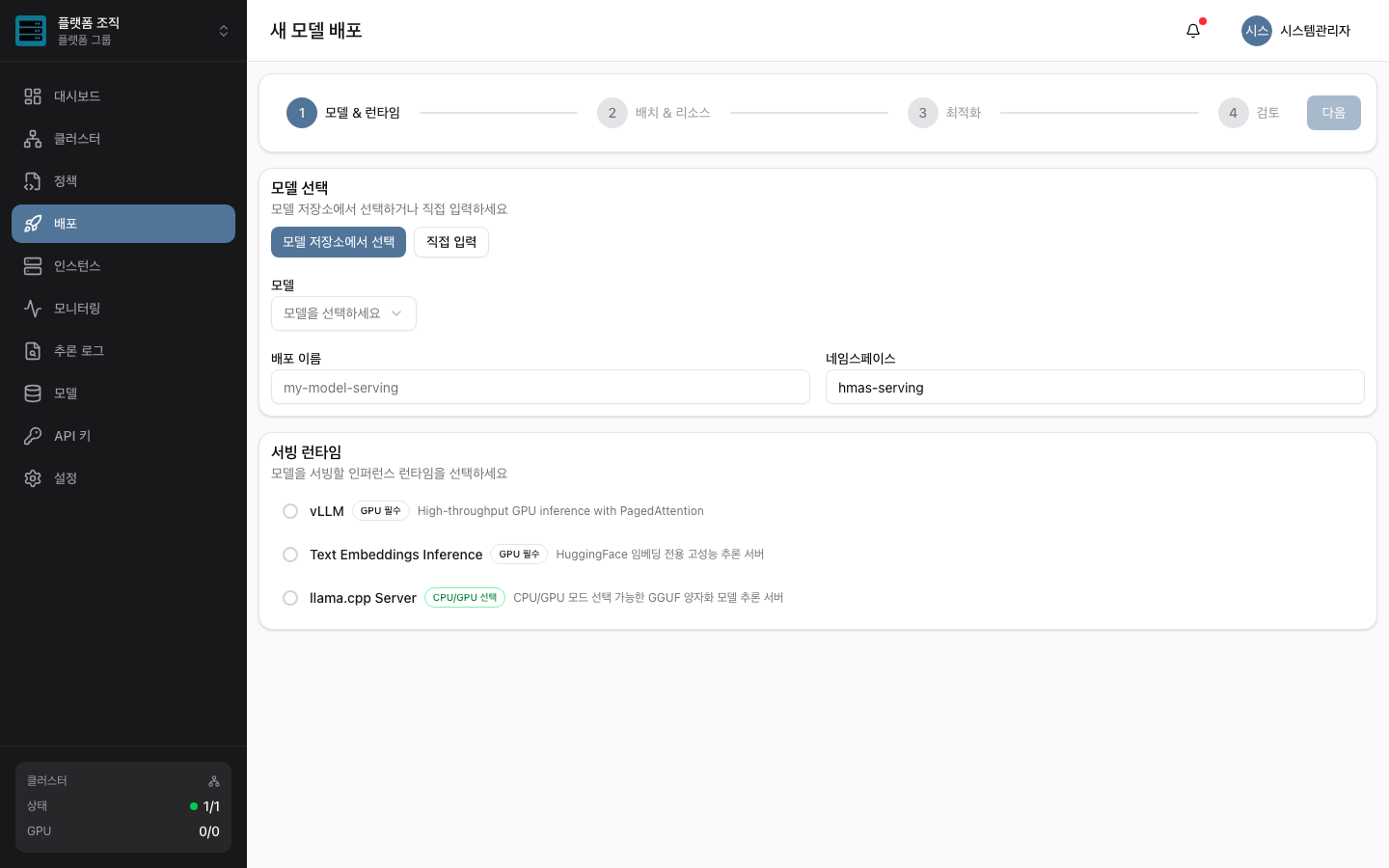
웹 콘솔에서 모델만 고르면 끝
관리자는 선택만, 나머지는 H-MAS가 자동으로 처리합니다.
WHY US
서빙 전용 + 온프레미스 + 토폴로지 인지
서빙 인프라가 갖춰야 할 네 가지를 H-MAS가 모두 충족합니다.
서빙 전용
학습이 아닌 서빙에 최적화된 설계.
온프레미스
클라우드를 못 쓰는 금융·공공·제조 환경에 그대로 설치.
토폴로지 인지 v0.9 로드맵
GPU 연결 구조를 인식해 통신 병목을 최소화하고 성능을 끌어올립니다.
멀티 클러스터
흩어진 GPU 서버를 하나의 컨트롤 플레인으로 통합.
GPU 3~20대를 보유한 중소·스타트업·연구소를 위한 가볍고 빠른 도입. 기존 추론 엔진(vLLM 등) 위에서 동작하는 인프라 관리 레이어입니다.
RELIABILITY
바로 도입할 수 있는 검증된 제품
컨셉이 아니라, 모델 등록부터 서빙·모니터링까지 실제로 동작하는 제품입니다.
- 검증된 배포 파이프라인 — 모델 등록 → 배포 → API 호출까지 멀티 클러스터에서 안정 동작
- 통합 추론 API — 모든 모델을 하나의 OpenAI 호환 엔드포인트로 호출
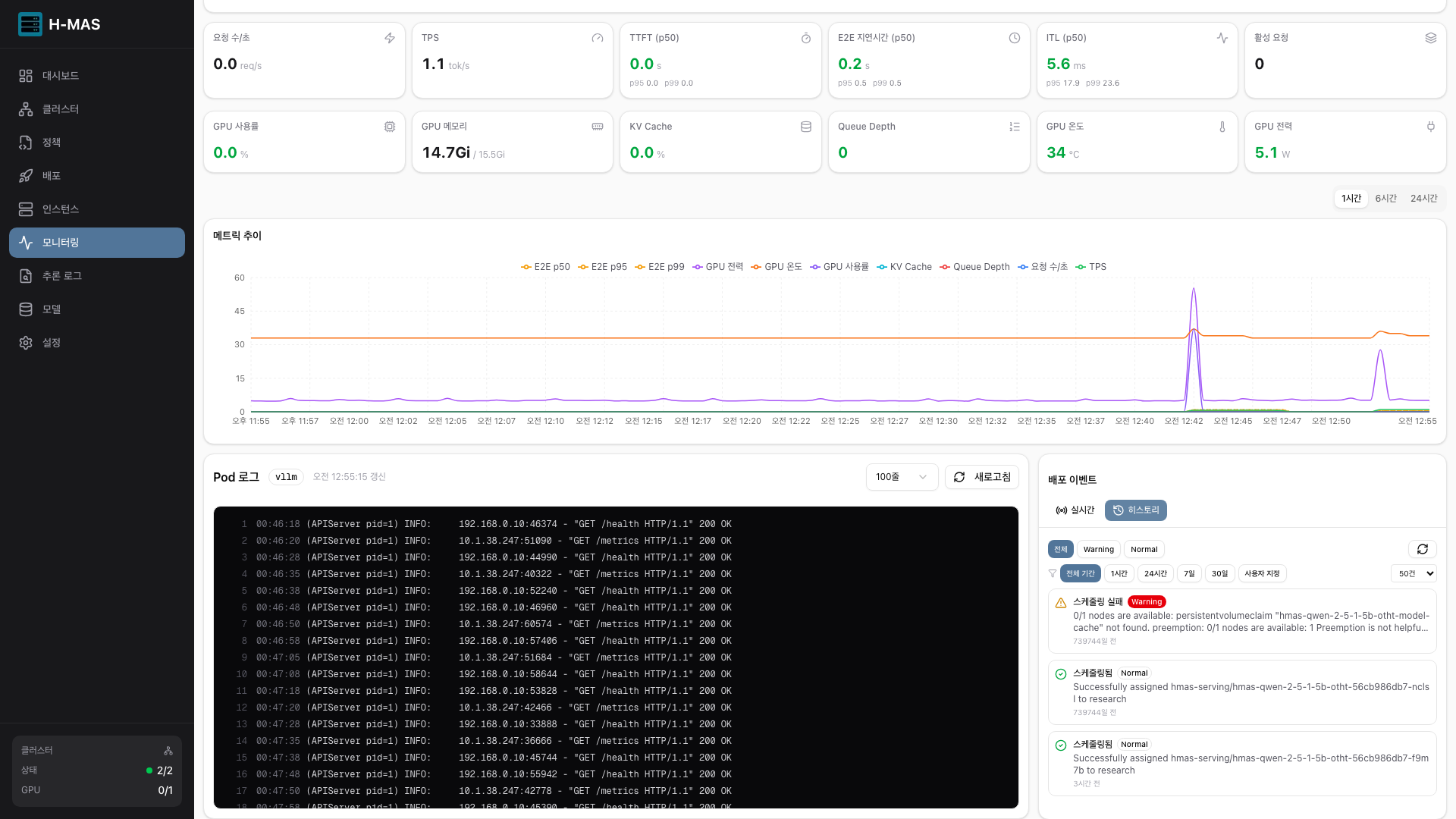
- 실시간 모니터링 — Prometheus 기반 TPS·지연시간·GPU 메트릭 제공
- 운영 안정성 — 이미지 사전 캐싱으로 재배포 시간 단축, 장애 자동 감지
- 지식재산권 확보 — 컴퓨터프로그램 저작권 등록 (한국저작권위원회 C-2026-020641)

WHO IT'S FOR
이런 분들께 H-MAS가 필요합니다
AI 비용의 대부분은 학습이 아니라 서빙에서 발생합니다. 자체 GPU를 두고도 제대로 활용하지 못하고 있다면.
자체 GPU를 보유한 기업
GPU 서버 3~20대를 두고 있지만 개별 운영되어 활용률이 낮은 AI 스타트업·중소기업.
클라우드를 못 쓰는 환경
보안 규정상 클라우드 사용이 불가해 자체 GPU + 온프레미스 서빙이 필요한 금융·공공·제조.
이기종 GPU 연구 조직
A100·RTX 등 여러 종류의 GPU를 묶어 모델별로 효율적으로 서빙하고 싶은 연구소·대학.
DEPLOYMENT
보유하신 환경에 직접 설치합니다
기존에 운영 중인 Kubernetes 환경 위에 온프레미스로 설치합니다. 데이터와 모델은 모두 고객 인프라 안에 머뭅니다.
온프레미스 구축형
고객사 GPU 인프라에 직접 설치·운영. 외부로 데이터가 나가지 않아 보안 규정이 엄격한 환경에도 적합합니다.
합리적인 운영 비용
이미 보유한 자체 GPU를 효율적으로 활용해, 시간당 과금되는 클라우드 GPU 대비 운영 비용 부담을 낮춥니다.
PoC부터 시작
보유하신 GPU 환경에 맞춰 PoC·데모를 먼저 진행합니다. 도입 규모와 조건은 환경에 맞춰 협의해 드립니다.
VISION
클라우드 없이도, AI를 가장 효율적으로
자체 GPU를 가진 모든 조직이 가장 효율적으로 AI를 서빙하는 표준을 만듭니다.
보유하신 GPU 환경에 맞춰 PoC·데모를 도와드립니다.