AI Weekly Picks(20251022)
Published:
AI Weekly Picks(20251022)
DGX-Spark
- 리뷰: https://lmsys.org/blog/2025-10-13-nvidia-dgx-spark/
NVIDIA DGX Spark는 로컬 AI 추론을 위해 설계된 소형 올인원 데스크톱 워크스테이션으로, 슈퍼컴퓨팅급 성능을 더 작은 폼팩터에 담았습니다.
샴페인 골드 마감의 풀메탈 섀시를 특징으로 하며, 20개의 CPU 코어를 통합하고 최대 1 PFLOP의 희소 FP4 텐서 성능을 제공하는 NVIDIA GB10 Grace Blackwell 슈퍼칩으로 구동됩니다. 이 시스템은 128GB의 일관된 통합 시스템 메모리를 자랑하여 데이터 전송 오버헤드 없이 대규모 모델을 직접 실행할 수 있으며, 더 큰 모델의 분산 추론을 위해 다른 DGX Spark 장치와 상호 연결할 수 있습니다. LPDDR5x 메모리 대역폭으로 인해 전체 크기의 개별 GPU 시스템에 비해 원시 성능은 제한되지만, 특히 소규모 모델 및 추측 디코딩을 사용한 프로토타이핑, 모델 실험 및 엣지-AI 연구에 탁월합니다. DGX Spark는 로컬 모델 서빙, 코딩 지원 및 AI 실험을 위한 개발자 친화적인 플랫폼으로 제시되며 접근성, 효율성 및 우아한 엔지니어링을 강조합니다. - 벤치마크: https://docs.google.com/spreadsheets/d/1SF1u0J2vJ-ou-R_Ry1JZQ0iscOZL8UKHpdVFr85tNLU/edit?gid=0#gid=0
nanochat
AGI is still a decade away
- Youtube: https://youtu.be/lXUZvyajciY?si=SeM2PjVTY3ouvg9z
- 스크립트: https://www.dwarkesh.com/p/andrej-karpathy?utm_campaign=post&utm_medium=web
- 스크립트(한글-진행중): https://docs.google.com/document/d/1B2UwKo_VHAZv_cVwmkIPri_WdbrSSisaJuSyZPV0-s0/edit?usp=sharing
Andrej Karpathy는 인간과 같이 기능하는 에이전트를 개발하는 데 상당한 작업이 필요하다는 점을 들어 AGI(인공 일반 지능)가 아직 약 10년은 더 걸릴 것이라고 생각합니다. 그는 현재의 강화 학습 방법이 신중한 검토와 복잡한 사고 과정을 통해 학습하는 인간과 달리, 보상을 할당하는 방식이 비효율적이고 잡음이 많아 “끔찍하다”고 주장합니다. 또한 Karpathy는 대규모 언어 모델이 강력하지만 새로운 코드를 다루거나 지식을 미묘한 방식으로 통합하는 데 어려움을 겪는 등 여전히 인지적 결함이 있다고 지적합니다. 이로 인해 완전한 자율 AI 엔지니어링보다는 자동 완성에 더 유용하다고 봅니다.
DeepSeek-OCR
- 데모: https://huggingface.co/spaces/khang119966/DeepSeek-OCR-DEMO
- 코드저장소: https://github.com/deepseek-ai/DeepSeek-OCR
- 논문: https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
DeepSeek-OCR 논문은 기존의 텍스트 토큰 대신 픽셀 기반 이미지 입력을 사용하여 컴퓨터 비전과 대규모 언어 모델(LLM)을 통합하는 중요한 발전을 소개합니다. 이 접근 방식은 보다 효율적인 정보 압축을 달성하고 텍스트 기반 토큰화의 한계를 극복하는 것을 목표로 합니다.
DeepSeek-OCR의 주요 측면과 혁신은 다음과 같습니다.
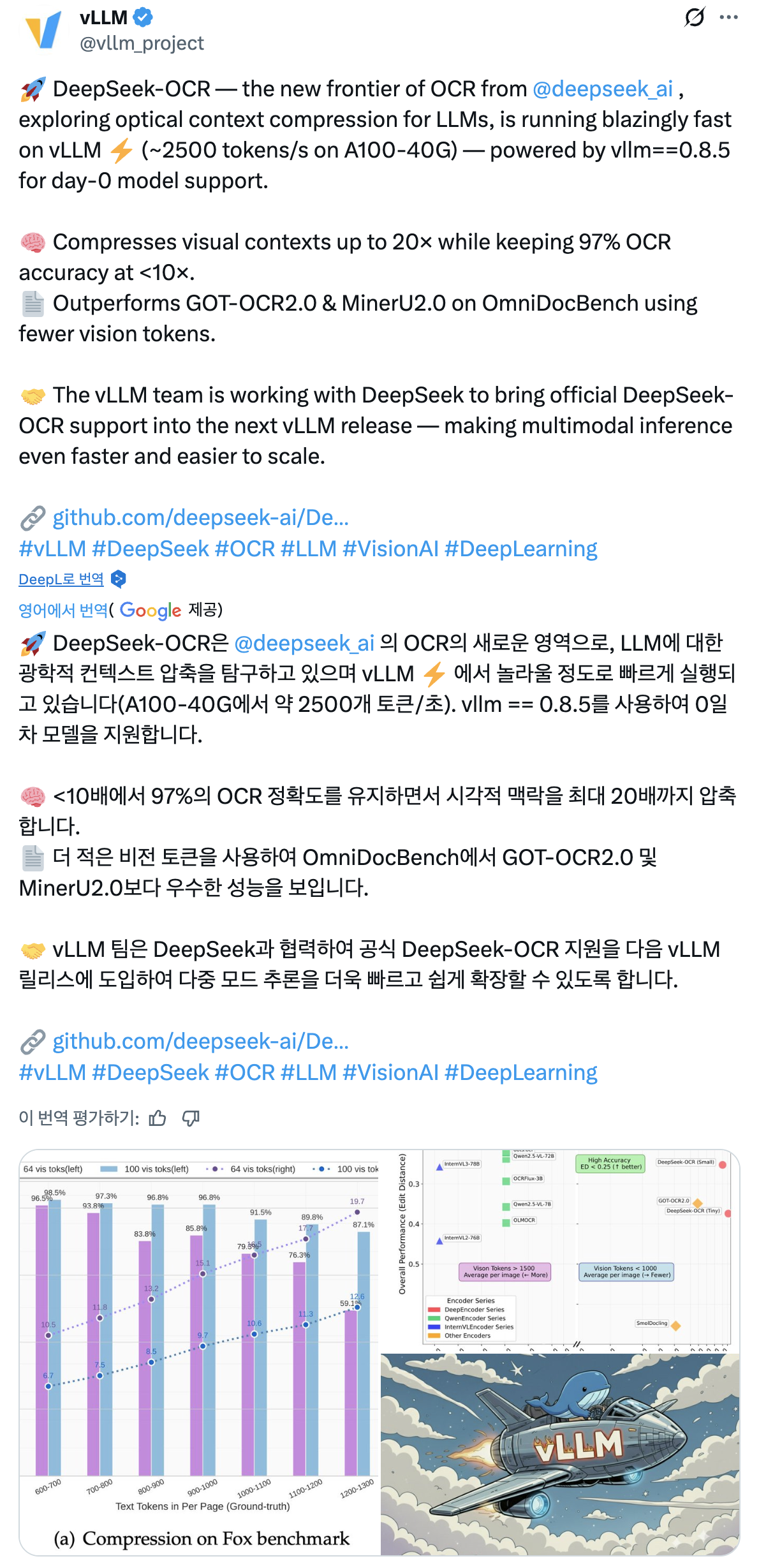
* 광학 압축: 핵심 아이디어는 이미지가 디지털 텍스트보다 텍스트 정보를 더 간결하게 표현하여 더 높은 압축률을 달성할 수 있다는 것입니다. 이 모델은 Fox 벤치마크에서 10배 압축률로 약 97%의 디코딩 정밀도를 달성하고 20배 압축에서도 유용한 동작을 보여 문서 처리에 필요한 토큰 수를 크게 줄입니다.
* 향상된 효율성 및 컨텍스트 창: 텍스트를 더 적은 “비전 토큰”으로 압축함으로써 DeepSeek-OCR은 LLM에 대해 더 짧은 컨텍스트 창과 더 높은 계산 효율성을 가능하게 합니다. 이는 기존 텍스트 토큰과 관련된 기하급수적으로 증가하는 컴퓨팅 성능 및 메모리 소비 없이 매우 긴 문서를 처리하는 데 중요합니다.
* “심층 구문 분석” 기능: 표준 OCR을 넘어 DeepSeek-OCR은 레이아웃 인식 및 OCR 2.0 기능을 갖춘 “심층 구문 분석”을 제공합니다. 차트에서 구조화된 정보 추출, 기하학적 도형 인식, 화학 구조식을 SMILES 형식으로 변환하는 등 다양한 문서 유형을 구문 분석할 수 있어 금융, 과학 및 STEM 분야에 유용합니다.
* 아키텍처: 이 시스템은 DeepEncoder와 Deepseek3B-MoE를 기반으로 구축된 텍스트 생성기의 두 가지 주요 부분으로 구성됩니다. DeepEncoder는 이미지 분할을 위한 Meta의 SAM(Segment Anything Model) 및 이미지와 텍스트를 연결하기 위한 OpenAI의 CLIP과 같은 구성 요소를 활용하며, 이미지 토큰을 대폭 줄이기 위한 16배 압축기를 함께 사용합니다.
* 광범위한 콘텐츠 처리: 이 비전 지향 접근 방식을 통해 LLM은 자동 회귀 텍스트 토큰화에서 종종 제한되는 양방향 주의를 통해 굵은 텍스트나 색상 있는 텍스트 및 임의의 이미지와 같은 광범위한 콘텐츠를 처리할 수 있습니다.
* 실용적인 응용: DeepSeek-OCR은 훨씬 적은 수의 토큰으로 벤치마크에서 GOT-OCR2.0 및 MinerU2.0과 같은 다른 모델을 능가하는 높은 실용적 가치를 가지고 있습니다. 대량의 학습 데이터를 효율적으로 생성하고 대규모 문서 이해 및 다중 모드 모델 학습을 지원할 수 있습니다.
전반적으로 DeepSeek-OCR은 AI에서 통합된 입력 양식으로의 전환을 나타내며, 잠재적으로 AI 파이프라인을 간소화하고 다양한 응용 분야를 위한 종단 간 다중 모드 AI 시스템에서 새로운 기회를 열어줍니다.
-