AI Weekly Picks(20251029)
Published:
AI Weekly Picks(20251029)
Claude Skills
https://www.anthropic.com/news/skills
Anthropic은 사용자가 지침, 스크립트 및 리소스가 포함된 폴더를 제공하여 특정 작업에 맞게 Claude를 사용자 지정할 수 있는 “Claude Skills”를 도입했습니다. Claude는 관련성이 있을 때 이러한 기술에 자동으로 액세스하므로 Excel 작업이나 브랜드 지침 준수와 같은 전문적인 작업을 보다 효율적으로 수행할 수 있습니다. 이러한 기술은 구성 가능하고 이식 가능하며 효율적이며 실행 가능한 코드를 포함할 수 있습니다. Claude 앱, Claude Code 및 Claude 개발자 플랫폼(API)에서 사용할 수 있으며 사용자 지정 기술을 생성, 관리 및 배포하는 기능이 있습니다.
https://www.anthropic.com/engineering/equipping-agents-for-the-real-world-with-agent-skills
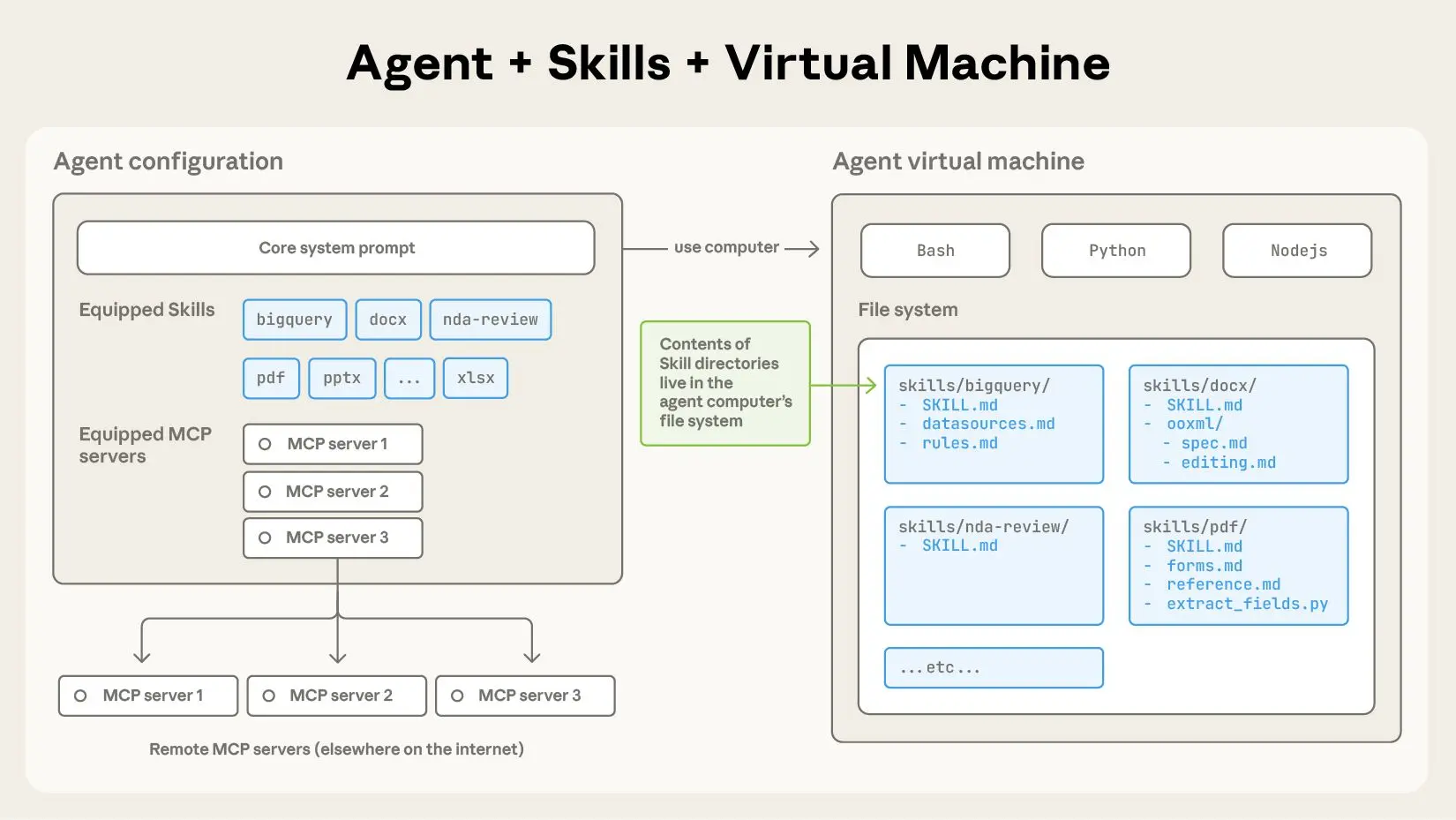
Anthropic은 지침, 스크립트 및 리소스를 폴더로 구성하여 전문 AI 에이전트를 만드는 새로운 방법인 “Agent Skills”을 도입했습니다. 이러한 Skill을 통해 Claude와 같은 범용 에이전트는 신입사원을 위한 온보딩 가이드와 유사하게 도메인별 전문 지식을 동적으로 로드할 수 있습니다. Skill은 점진적 공개를 위해 메타데이터와 함께 SKILL.md 파일을 사용하여 Claude가 관련 정보에 효율적으로 액세스하고 PDF 조작과 같은 작업을 위한 코드를 실행할 수도 있도록 합니다. 이 접근 방식은 신뢰할 수 없는 소스의 Skill을 감사하라는 보안 권장 사항과 함께 에이전트 기능, 확장성 및 이식성을 향상시킵니다.
ChatGPT Atlas
- https://chatgpt.com/ko-KR/atlas/
- https://techcrunch.com/2025/10/21/openai-launches-an-ai-powered-browser-chatgpt-atlas/
Agent Pattern 17가지
다양한 에이전트 설계 패턴을 통합하여 대규모 AI 시스템을 구축하는 방법을 설명합니다.
각 패턴에는 고유한 단계, 빌드 방법, 출력 및 평가 프로세스가 있습니다.
Now Serving NVIDIA Nemotron with vLLM
https://blog.vllm.ai/2025/10/23/now_serving_nvidia_nemotron_with_vllm.html
vLLM은 이제 NVIDIA에서 개발한 개방형 AI 모델 제품군인 Nemotron을 공식적으로 지원합니다. Nemotron은 특히 에이전트 AI 시스템 구축을 위해 설계되었으며, vLLM을 통해 개발자들은 이러한 강력한 모델을 매우 효율적으로 배포하고 운영할 수 있게 되었습니다.
주요 특징 및 성능:
- 새로운 아키텍처 (Nemotron Nano 2): 새롭게 소개된 Nemotron Nano 2 모델은 기존의 Transformer와 새로운 Mamba 아키텍처를 결합한 하이브리드 구조를 가집니다. 이는 모델이 더 빠르고 효율적으로. 작동하도록 돕습니다.
- 높은 정확도 (Figure 1 참조): 함께 제공된 성능 그래프(Figure 1)에 따르면, Nemotron Nano 2 모델은 추론, 코딩, 에이전트 관련 작업 등 다양한 벤치마크에서 매우 높은 정확도를 기록했습니다. 이는 Nemotron이 복잡하고 다단계의 작업을 처리하는 데 매우 효과적이라는 것을 시각적으로 보여줍니다.
- ‘사고 예산(Thinking Budget)’ 기능 (Figure 2 참조): Nemotron 모델의 가장 독특한 기능 중 하나는 “사고 예산”입니다. 이 기능은 모델이 답변을 생성하기 전에 얼마나 깊게 “생각”할지(추론에 사용할 토큰의 양)를 개발자가 직접 설정할 수 있게 해줍니다. 두번째 그래프(Figure 2)는 이 “사고 예산”을 조절함으로써 추론 비용과 정확도 사이의 최적의 균형점을 찾을 수 있음을 보여줍니다. 예를 들어, 간단한 작업에는 낮은 예산을 할당하여 비용을 절약하고, 복잡한 작업에는 높은 예산을 할당하여 정확도를 높일 수 있습니다.
결론: 이번 vLLM의 Nemotron 지원은 개발자들이 차세대 에이전트 AI를 구축하는 데 있어 큰 이점을 제공합니다. 개발자들은 vLLM의 높은 처리량과 효율적인 서빙 능력을 바탕으로, Nemotron 모델의 강력한 성능과 “사고 예산”과 같은 독특하고 유연한 기능을 최대한 활용할 수 있게 되었습니다. 이를 통해 더 빠르고, 더 저렴하며, 더 정확한 AI 에이전트 서비스를 개발하고 배포할 수 있습니다.
PyTorch 재단에 합류한 Ray
https://www.anyscale.com/blog/ray-by-anyscale-joins-pytorch-foundation
Ray는 PyTorch Foundation에 합류했습니다.
이는 Ray의 급격한 성장(지난해 다운로드 10배 증가)과 AI 워크로드 확장에 대한 필요성 증가에 따른 것입니다. Ray는 원래 UC Berkeley에서 AI 알고리즘 확장을 위해 시작되었으며, 2019년 Anyscale이 상용화를 시작했습니다. 생성형 AI와 LLM의 등장으로 Ray의 확장 필요성이 더욱 커졌습니다. PyTorch가 딥러닝 프레임워크의 표준인 것처럼, Ray는 오픈소스 분산 컴퓨팅 엔진으로서 AI 컴퓨팅 스택의 표준이 되는 것을 목표로 합니다. Ray는 PyTorch Foundation 합류를 통해 글로벌 기여자 커뮤니티를 확장하고 AI 인프라의 미래를 계속해서 만들어 나갈 계획입니다.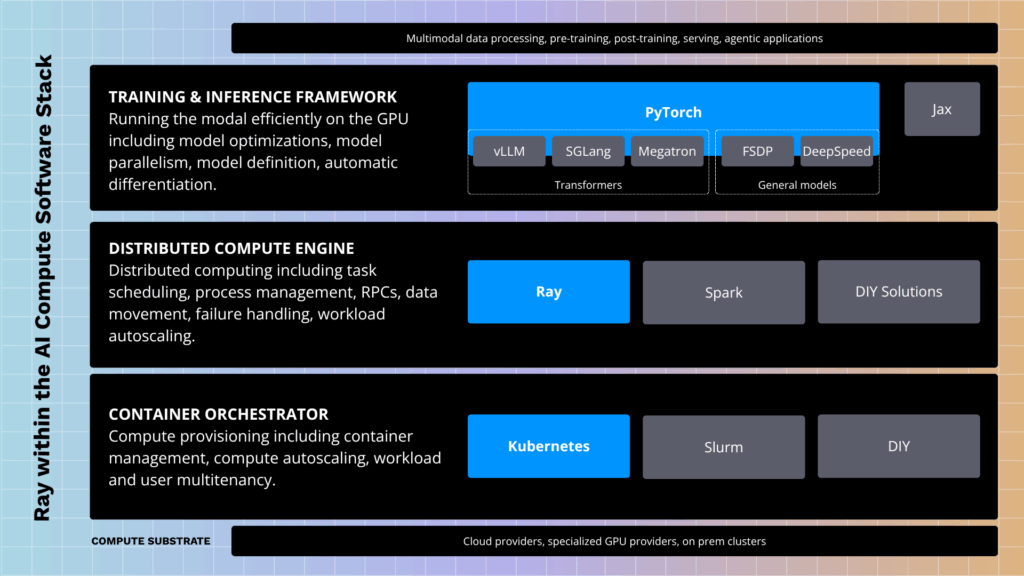
PyTorch 재단에 Ray가 합류했습니다. Ray는 AI 워크로드를 대규모로 처리하기 위한 오픈소스 분산 컴퓨팅 프레임워크입니다. 이번 통합은 AI 컴퓨팅 스택을 통합하고 개발자가 AI 모델을 더 쉽게 확장하고 배포할 수 있도록 돕는 것을 목표로 합니다.
MiniMax M2
https://huggingface.co/MiniMaxAI/MiniMax-M2
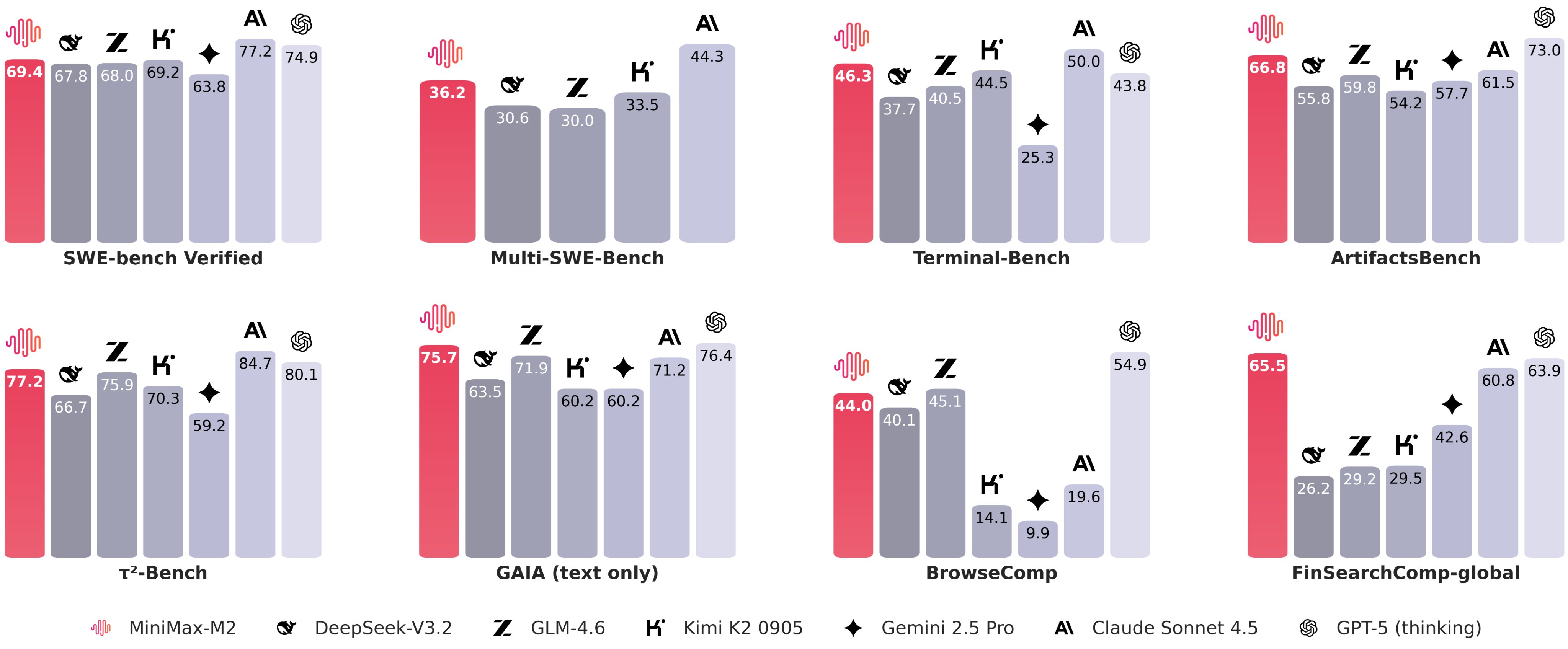
claude Sonnet 가격의 8%에 약 2배 빠른 속도
임베딩 모델의 파인튜닝
https://weaviate.io/blog/fine-tune-embedding-model
맞춤형 임베딩 모델을 파인튜닝하는 이유, 시기, 방법에 대한 포괄적인 개요를 제공합니다. 특히 RAG 시스템에서 도메인별 지식을 더 잘 포착하여 검색 성능을 향상시키기 위해 기본 임베딩 모델을 사용자 정의하는 것의 이점을 설명합니다. 또한 파인튜닝을 수행하기 전에 키워드 검색 또는 청킹 기술과 같은 다른 문제 해결 단계를 고려해야 하는 경우를 포함하여 파인튜닝을 언제 피해야 하는지에 대한 실용적인 조언을 제공합니다. 주요 고려 사항에는 비용, 적절한 기반 모델 선택, 고품질 훈련 데이터셋 작성, 대조적 손실 함수 사용을 포함한 파인튜닝 프로세스가 포함됩니다. 마지막으로, 이 글은 파인튜닝된 모델을 Hugging Face 또는 Amazon SageMaker 통합을 통해 Weaviate 벡터 데이터베이스와 함께 사용하는 구체적인 방법을 안내합니다.
vLLM으로 Nemotron 서빙
https://blog.vllm.ai/2025/10/23/now_serving_nvidia_nemotron_with_vllm.html
vLLM은 에이전트 AI 시스템을 위해 설계된 개방형 모델 제품군인 NVIDIA Nemotron을 지원한다고 발표했습니다. 최신 추가 사항인 Nemotron Nano 2는 하이브리드 Transformer-Mamba 아키텍처와 정확성, 처리량 및 비용을 최적화하기 위한 구성 가능한 “사고 예산”을 특징으로 합니다. vLLM은 Nemotron 모델의 효율적인 배포를 가능하게 하여 더 빠른 추론과 더 나은 메모리 관리를 제공합니다.