AI Weekly Picks(20251203)
Published:
AI Weekly Picks(20251203)
On-Policy Distillation
- https://thinkingmachines.ai/blog/on-policy-distillation/
- “On-Policy Distillation”이라는 Thinking Machines Lab의 기사는 더 작은 언어 모델을 효율적으로 훈련하는 방법을 소개합니다. 이 기술은 학생 모델이 자체 생성 궤적에서 학습하는 On-Policy 훈련과 증류를 통해 더 큰 교사 모델의 밀도 높은 피드백을 결합합니다. 이 접근 방식은 특히 수학적 추론 및 개인화된 AI 비서 생성과 같은 작업에서 기존 강화 학습 및 오프-정책 증류에 대한 비용 효율적인 대안으로 제시됩니다. 이는 지속적인 학습 중 성능 저하를 방>지하고 계산 효율성을 향상시키는 것을 목표로 합니다.
Build a SIMPLE Text-to-SQL Agent
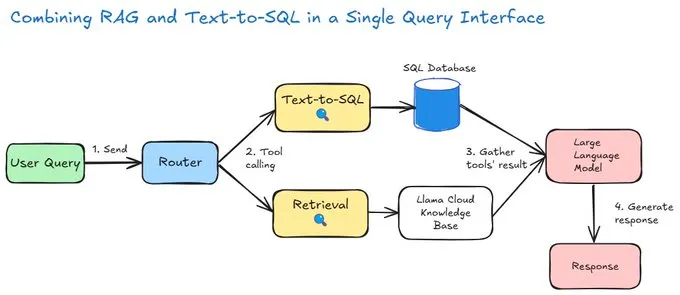
https://lukedinh1501.medium.com/build-a-simple-text-to-sql-agent-4f58490a8b23
자료는 특정 인공지능 및 데이터베이스 도구를 사용하여 간단한 Text-to-SQL 에이전트를 구축하는 방법을 설명하며, 작성자는 자신의 복잡한 과거 경험과 대조하며 이 모델의 단순함을 강조합니다. 이 과정은 프로세스 오케스트레이션을 위한 Llama-index와 로컬 SQL 데이터베이스 생성을 위한 SQLAlchemy를 포함한 필수 기술 스택을 상세히 다룹니다. 사용자 지정 에이전트는 내부적으로 라우터 역할을 수행하여, 질문을 표준 SQL 엔진으로 보낼지 또는 LlamaCloud 벡터 데이터베이스를 통한 RAG 검색으로 보낼지 결정하는 이중 기능 도구를 사용합니다. 아티클은 RouterOutputAgentWorkflow 클래스를 중심으로 한 복잡한 작업 흐름을 단계별로 분석하며, 사용자의 메시지를 처리하고 도구 호출 결과를 모으는 과정을 보여줍니다. 작성자는 이 예시가 교육 목적임을 강조하고, 수백 개의 테이블과 보안 문제가 얽힌 실제 은행 환경에서의 엔터프라이즈급 복잡성은 다음 기사에서 다룰 것이라고 예고하며 글을 마칩니다.
Introduction to distributed inference with llm-d
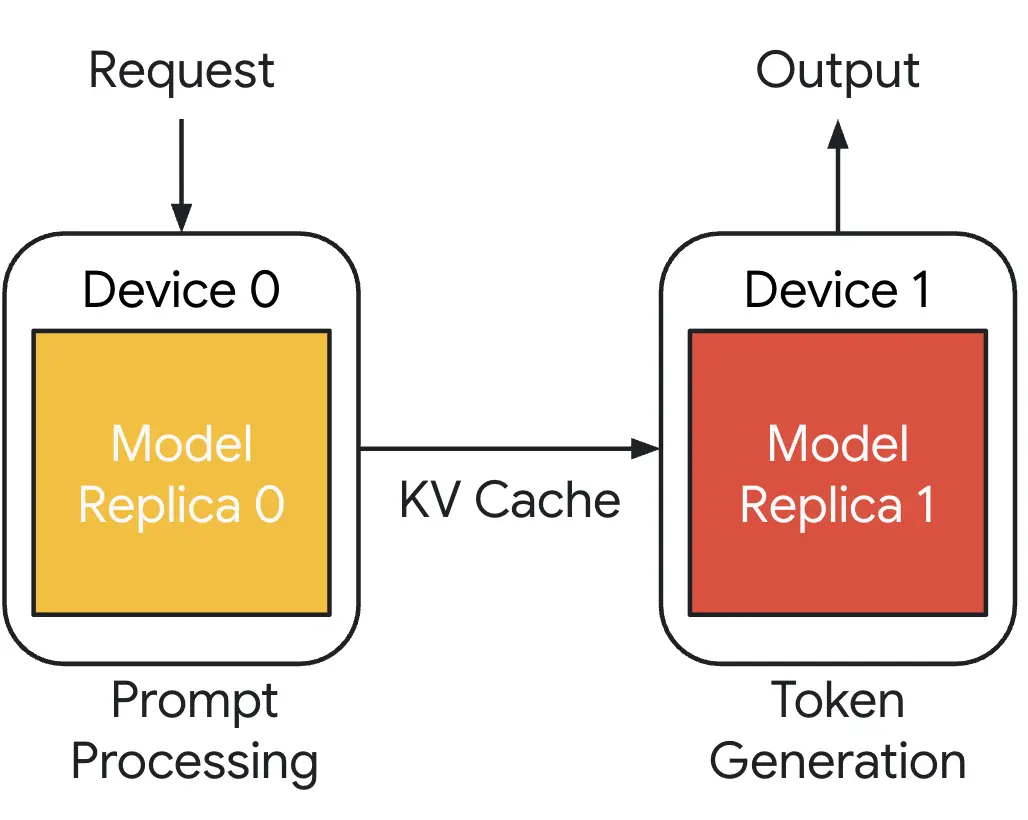
- https://developers.redhat.com/articles/2025/11/21/introduction-distributed-inference-llm-d
- 이 글에서는 대규모 언어 모델(LLM)의 분산 추론을 위한 오픈소스 프로젝트인 llm-d를 소개합니다. llm-d는 분산 추론, 캐시 인식 라우팅, 그리고 MoE를 활용하여 성능과 리소스 활용을 향상시킴으로써 기존 LLM 추론의 문제점을 해결합니다. 이 프로젝트는 OpenShift를 활용하며, LLM 추론을 엔터프라이즈급 및 크로스 플랫폼으로 구현하는 것을 목표로 합니다.